AgentBreeder
Mitigating the AI Safety Impact of Multi-Agent Scaffolds via Self-Improvement

Abstract
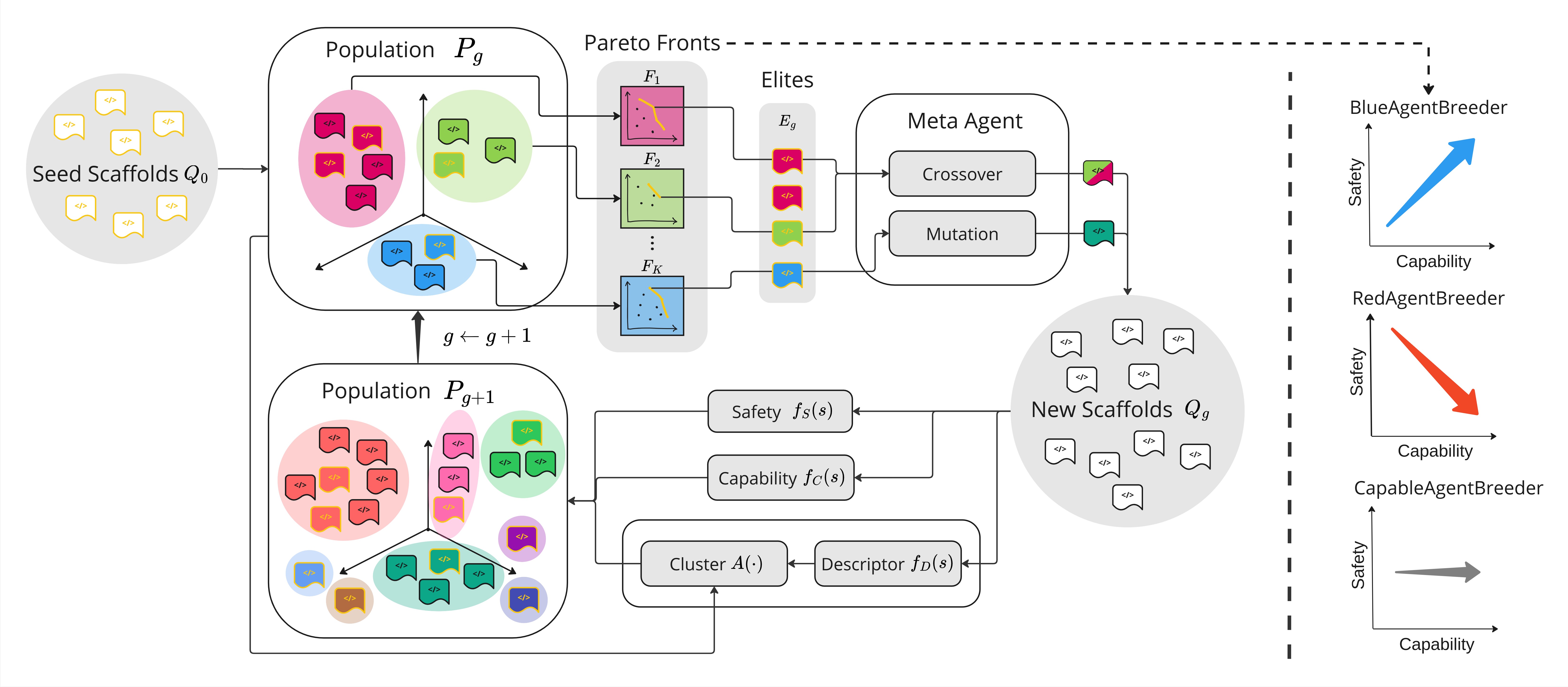
Scaffolding Large Language Models (LLMs) into multi-agent systems often improves performance on complex tasks, but the safety impact of such scaffolds has not been thoroughly explored. We introduce AgentBreeder, a framework for multi-objective self-improving evolutionary search over scaffolds, specifically targeting scaffolds' safety impact on large language models in multi-agent systems.
We evaluate discovered scaffolds on widely recognized reasoning, mathematics, and safety benchmarks. In 'blue' mode, we see a 79.4% average uplift in safety benchmark performance while maintaining or improving capability scores. In 'red' mode, we find adversarially weak scaffolds emerging concurrently with capability optimization. Our work demonstrates the risks of multi-agent scaffolding and provides a framework for mitigating them.
Key Achievements
- 🎯 79.4% average uplift in safety benchmark performance while maintaining capability
- 🔬 First framework for multi-objective evolutionary search over multi-agent scaffolds
- ⚖️ Balanced optimization of safety and capability through Pareto optimization
- 🔴 Red-team insights revealing how capable scaffolds can become highly vulnerable
- 📊 Comprehensive evaluation across DROP, MMLU, GPQA, and SaladData benchmarks
Operational Modes
AgentBreeder operates in three distinct modes, each serving different research and deployment needs:
🔵 BlueAgentBreeder (Defense)
- Objective: Maximize both safety and capability
- Use case: Develop robust, safe multi-agent systems
- Result: 79.4% average safety improvement while maintaining capability
BlueAgentBreeder focuses on creating scaffolds that enhance both the safety and performance of multi-agent systems. This mode is ideal for production deployments where safety is paramount.
🔴 RedAgentBreeder (Attack)
- Objective: Maximize capability while minimizing safety
- Use case: Red-team testing and vulnerability discovery
- Result: Reveals how scaffolding can inadvertently expose safety weaknesses
RedAgentBreeder serves as an adversarial testing tool, helping researchers understand potential vulnerabilities in multi-agent scaffolds. This mode is crucial for identifying safety risks before deployment.
🎯 CapableAgentBreeder (Capability)
- Objective: Maximize capability only
- Use case: Baseline comparison and pure performance optimization
- Result: Competitive performance with existing approaches
CapableAgentBreeder provides a baseline for comparison by focusing solely on performance optimization without safety constraints.